Deepseek的新论文mHC,给我一种大模型重回黑盒的感觉
新年的节点,Deepseek又发了一篇论文,是针对于传统的residual的解法,提出了mHC,非常漂亮的论文。
可能有点儿不是很政治正确,我的感觉的确跟reddit这个哥们非常的相似。

翻译过来是这样的:
这一切动态化,或者说由 llm 生成,这一天应该很快就会到来。尽管我对 DeepSeek 的工作印象深刻,但我已经懒得再去学习这些架构了。我怀疑自己能否做出贡献。所以,我只会把它们当作带有“参数”的“黑盒”来对待。真是令人叹为观止!
他的评价很直接,就是一方面表示对于deepseek工作的夸奖(impressed),另一方面也有点儿对于层出不穷框架的学习力竭感。
他现在对于这些框架architecture的态度回到了最初对于deep learning印象的起点,那就是含有大量参数的黑盒模型(black boxes)。
当然,他这番话也收到了将近40个人的点踩。
因为的确不够技术,不够积极,不够昂扬。
但实际上我也是这样感觉的,当然我是在看了论文之后,发现它要解决的问题其实是字节豆包团队之前提出的一个针对于residual的解法,其实非常像“富贵病”。
传统 residual 的单向、简单叠加,本身是极其安全、极其稳妥的设计。它几乎不会犯错,但代价也很明显:在很多情况下,一些本来可能有价值的信息,并没有真正参与到后续的表示构建中,而是被“安全地”淹没掉了。
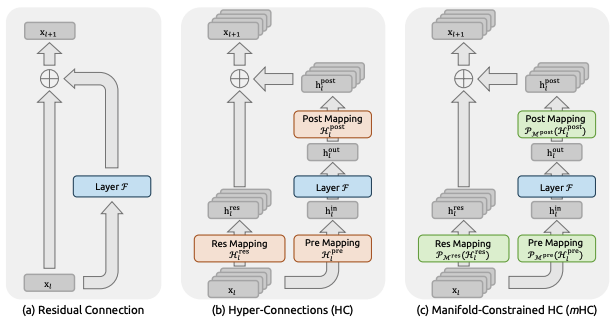
字节豆包团队此前提出的 HC(Hyper-Connections),正是试图解决这个问题:既然信息可能被浪费,那就干脆把 residual 拆成多路,让它们之间产生更充分的交互。
但 HC 的问题也同样明显——一旦规模上去,多路 residual 在深层叠加之后,很容易带来数值不稳定和训练风险。这不是实现细节的问题,而是结构本身缺乏约束。
DeepSeek 提出的 mHC,其实是一种非常优雅、也非常“工程正确”的回应:通过引入流形约束,把这种多路 residual 的交互限制在一个稳定的空间里,让信息可以更充分地混合,但又不至于失控。
从设计上说,这是一条非常漂亮的技术路径。
但给我的感觉就是现在的大模型已经处于水多加面,面多加水的阶段了,在没有革命性的新材料发现之前,水和面的比例只能通过一次次的试错才能解出来。
特别是换个容器、换个环境、换个人来操作,可能都不太一样。
在这种背景下,把模型重新视为一个带参数的黑盒,并不意味着否定这些工作的价值,而更像是一种位置上的战略回撤:从执着于理解每一条内部连接,转向关注系统的整体行为、稳定边界以及可控性。
再往前看一步,我甚至会觉得,那位 Reddit 用户的判断,未必只是情绪化的“疲惫”,而可能无意中触碰到了一个更长远的趋势。
当前的大模型,无论是 residual 的加法,还是流形约束下的乘法,本质上仍然是静态结构。即便参数再多、设计再复杂,只要 seed 固定,训练过程和最终行为在统计意义上都是高度可复现的。此前也已经有论文指出,在这种前提下,模型输出的一致性是可以被严格保证的。
如果真是这样,那么或许真正不变的,并不应该是某一种固定结构或固定配方,而应该是结构和参数在训练过程中的动态调整能力。
也许在未来,pre-train 本身会被某种“自定义的 LLM”部分取代:模型不再只是遵循预先写死的数学或物理公式,而是能够在训练甚至推理过程中,动态地修改自己的结构、路径乃至参数分配方式。
如果那一天真的到来,那么今天这些精妙却静态的架构,很可能都会成为过渡形态。
回到最初那条 Reddit 评论,我现在反而觉得,它之所以被点踩,并不是因为它错了,而是因为它说得太早、也太直接了。
当模型已经进入“水多加面、面多加水”的阶段时,承认个体在架构层面的边际贡献正在下降,也许并不是一种消极,而是一种对现实复杂度的诚实回应。